STIC is the primary luminosity device in DELPHI and is used for luminosity measurement online as well as offline. The VSAT detector is sitting closer to the beam pipe and has thus a much higher cross section for bhabhas, which is the process used for luminosity measurement. Bigger cross section results in more statistics and smaller statistical errors, which gives the VSAT an advantage over STIC for small data sizes. VSAT is also used to test the stability and functionality of the STIC detector. Without the luminosity cross check with the VSAT, STIC would have an undesirable uncertainty of its stability for individual cassettes.
As have been pointed out before there are many parameters and beam conditions that influence the VSAT cross section for bhabhas [11]. This results in that the detector cannot provide an accurate absolute measurement of the luminosity. It is however possible to normalize it to the STIC luminosity for datataking periods with similar conditions.
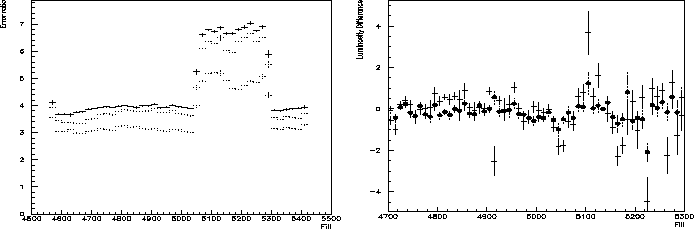
After this normalization the VSAT data can be used to measure the luminosity within these periods, with a much better statistical error than the STIC detector [12]. With no downscaling for both detectors we have after all corrections about 4 times better statistical error than STIC(fig 4.11). The false bhabha rate naturally pulls down this advantage a bit, but not to a big extent as can be seen in fig 4.11. Here it is also easy to follow the down scaling by a factor two of the STIC detector at fill 5047 and the same factor two of VSAT at fill 5296.
 |
Besides the statistical error the VSAT naturally has a systematical error as well, which becomes more important with the data size. The VSAT cross section fluctuates with certain conditions of the beam, which gives rise to systematical errors in the luminosity. It is however possible to measure a number of beam parameters with the VSAT and correct the luminosity for these fluctuations. The dependence of these parameters can be extracted either by looking on Monte-Carlo simulations or comparing directly to the STIC data.
It is naturally much easier and faster to compare directly to the STIC data, as the final comparison is done to this anyway. A problem arises here however, if the data is just fitted to STIC data it is possible that the fit just makes a bad carbon copy of the STIC data, rather than reflecting actual fluctuation of the VSAT cross section. Special care is therefore taken so that statistical fluctuations of the STIC luminosity do not influence the fitting procedure.
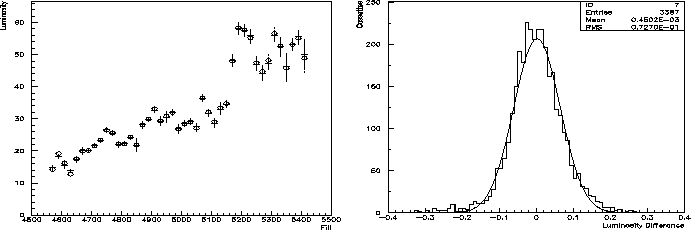
This problem is solved by grouping STIC and VSAT data in blocks of different sizes [13]. For each block size a Monte Carlo fit is done and parameters common from all the fits are extracted. The result of this correction per cassette of the VSAT cross section can be seen in fig 4.12, where the STIC and VSAT luminosity difference have been plotted before and after the beam parameter fit.
When all the corrections have been applied to the data, a final comparison is done with STIC for the whole year(fig 4.13). The systematical error of the VSAT is then finally estimated by taking the relative luminosity difference between STIC and VSAT data(fig 4.14). By normalizing this distribution with the statistical errors from both STIC and VSAT it is possible to make a coarse estimation of the VSAT systematical error. For 1997 and 1998 it was found to be about 1%, which naturally has an impact on the STIC to VSAT error ratio(bottom curve in fig 4.11).
 |